Take Our Content to Go
In this white paper, Mosaic ATM developed Visual Integration of Language Models in Automotive Safety (VILMAS), a context-aware system that enhances driver safety by integrating visual-language models with computer vision and deep learning to assess real-time driver readiness.
Introduction of Language Models in Automotive Safety
Mosaic ATM partnered with Touchstone Evaluations (Touchstone) to complete Phase I of the Visual Integration of Language Models in Automotive Safety (VILMAS) Small Business Innovation Research (SBIR) project, funded through the National Highway Traffic Safety Administration (NHTSA). VILMAS is designed to enhance driver safety by developing a fully context-aware system that evaluates “driver readiness” in real time. This system integrates state-of-the-art visual-language models (VLMs) with existing computer vision (CV) and deep learning methodologies to assess both “what’s happening” and “what might happen” based on detected behaviors and environmental conditions. Phase I developed proof-of-concepts while Phase II shall integrate these models and human factors into a unified system.
The Problem: Improving Driver Readiness Assessment
Current automotive safety systems rely on partial indicators of driver readiness, such as gaze tracking and object detection, but lack a comprehensive approach that accounts for both the driver’s internal state and external environmental conditions. Traditional approaches focus on isolated signals like eye closure rates (PERCLOS) or lane departure warnings, which only provide fragmented insights into driver readiness. These systems do not integrate multiple contextual cues into a unified model, limiting their ability to predict driver behavior accurately. Furthermore, commercial viability is hampered by licensing restrictions and hardware/software integrations. By combining VLMs, gaze tracking, deep learning, and human factors research, VILMAS aims to create a truly holistic driver readiness assessment that adapts dynamically to road conditions and driver behaviors.
Project Startup and Infrastructure Development
Mosaic initiated Phase I by hosting a kickoff meeting with NHTSA’s technical point of contact (TPOC) to define project requirements and scope. The team established project timelines, reporting structures, and development milestones to align with NHTSA guidelines. To support the secure storage and computational needs for VILMAS, Mosaic provisioned cloud-based infrastructure using Amazon Web Services (AWS), ensuring that large-scale datasets and computationally intensive models could be processed efficiently.
Data Collection and Aggregation for Language Models in Automotive Safety
To build robust AI models for Language Models in Automotive Safety, Mosaic aggregated and formatted multiple open-source datasets, selecting those most relevant to:
- Gaze dataset containing >37k annotated images for direction of gaze. This data includes 20 unique participants under different lighting conditions with an (x,y,z) gaze vector pointing from center-of-head to a location on a computer screen in front of the subject. This shall be used to create locus-of-gaze detection routines.
- KaggleEyes dataset containing >10k grayscale images of pre-cropped eye regions with a binary label of “open” or “closed”.
- UnityEyes dataset containing 3k red / green / blue (RGB) images of computer-generated eye regions of either “open” or “drowsy” eye where drowsy is defined to be 80% eye closure.
- StateFarmDistracted dataset containing >10k images in a vehicle environment with 11 categorical labels such as “texting”, “calling”, “hair/makeup”, and others.
- Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) Vision Benchmark with annotated frames and MS COCO (Microsoft Common Objects in Context) dataset for external object detection. This dataset is a large-scale object detection, segmentation, and captioning dataset. It contains 80 classes of objects, several of which are of use in this context including person, car, bicycle, and motorcycle. These objects are typically included in diverse contexts within the dataset.
- For the lane detection algorithm prototyping we have downloaded and formatted the ONCE-3DLanes dataset. This dataset leverages images from the ONCE dataset, which includes images, light detection and ranging (LIDAR), and annotations for object detection and localization. The ONCE-3DLanes dataset provides annotations of the lanes within the images in the original set. The test set includes 8,000 images.

Figure 1: Open-source dataset examples used in VILMAS
These annotated datasets (Figure 1) were used to generate quantitative still-frame metrics to validate the models prior to future implementation on streaming video data. In parallel, Touchstone collected data to be used for experimental verification of these subsystems. This includes approximately 5h of streaming high definition (HD) video collected with the VBOX hardware.
The platform, originally intended for motorsports applications providing both video data logging and optional telemetry in a single unified platform. More information and technical specification can be found at VBOX Motosports — which serves as a representative system of the type of hardware platform that wouldbe used in a deployed version of VILMAS.
Attention Detection Algorithms for Language Models in Automotive Safety
Mosaic developed two primary systems for attention detection: one leveraging visual language models (VLMs) for driver activity recognition and another utilizing conventional gaze monitoring techniques.
Visual Language Modeling for Driver Activity Recognition
The VLM-based approach initially used a locally hostable LLaVA-NeXT model to generate natural language descriptions of driver actions, such as mobile phone use, eating, or adjusting controls. While effective at generating descriptive insights, this approach proved computationally expensive, requiring approximately two seconds per inference.

Figure 2:Touchstone data capture for VLM analysis
To address this, Mosaic ATM explored using the Contrastive Language Image Pre-Training (CLIP) model to identify actions. Essentially, the full VLM (LLaVA-NeXT) combines an image-caption scoring model like CLIP with a large language model (LLM) for natural language question-answering. By directly using the image-caption model instead of the full VLM LLaVA, the team was able to quantify results with improved runtime efficiency.
For example, in Figure 2, the image of a driver using a cell phone scores higher on the caption “person driving a car while using a cell phone” compared to the background caption “person driving a car” (0.5095 vs. 0.4905). The inverse is true for an image of a driver not using a cell phone (0.4912 vs. 0.5088).
Mosaic ATM’s team pivoted to using CLIP, which powers the image recognition portion of full VLMs like LLaVA. By applying cosine similarity scoring, the team matched captions such as “person driving a car” against “person driving a car using a cell phone.” Using the openly available distracted driving dataset, Mosaic identified 10 possible action categories:
- c0: Safe driving
- c1: Texting – right
- c2: Talking on the phone – right
- c3: Texting – left
- c4: Talking on the phone – left
- c5: Operating the radio
- c6: Drinking
- c7: Reaching behind
- c8: Hair and makeup
- c9: Talking to passenger
Based on initial experimentation, the team aggregated classes c1-c4 into a single “mobile phone usage” category and used CLIP to differentiate images of mobile phone use from safe driving.
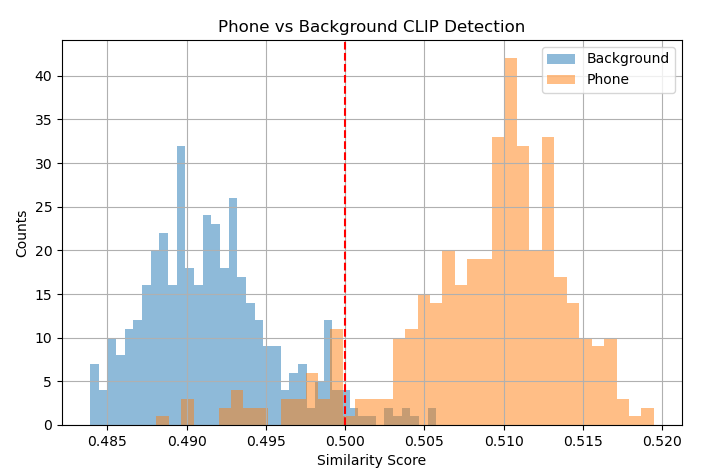
Figure 3: CLIP similarity score clustering for safe driving versus mobile phone usage
As shown in Figure 3, the similarity score represents the numerical cosine similarity between the target image and captions such as “Person driving a car” versus “Person driving a car while using a cell phone.” While not a conventional probabilistic confidence score used in categorical detection, this can be similarly quantified using the area-under-the-curve (AUC) for receiver operating characteristics (ROC) (Figure 4).
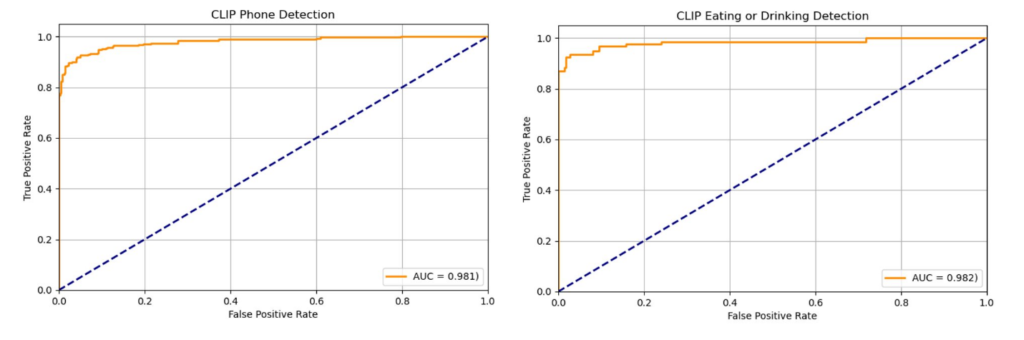
Figure 4: ROC Curves for mobile phone and eating or drinking detection
In Figure 5, Mosaic ATM’s team observed an AUC of approximately 0.98 when using CLIP to detect mobile phone usage and eating or drinking, demonstrating its effectiveness as a classifier. The team then expanded detection to additional actions using the following captions:
- “Person driving car without distractions”
- “Person driving and using cell phone”
- “Person driving and eating or drinking”
- “Person driving and adjusting hair or applying makeup”
- “Person driving and reaching for infotainment”
- “Person driving and reaching for object”
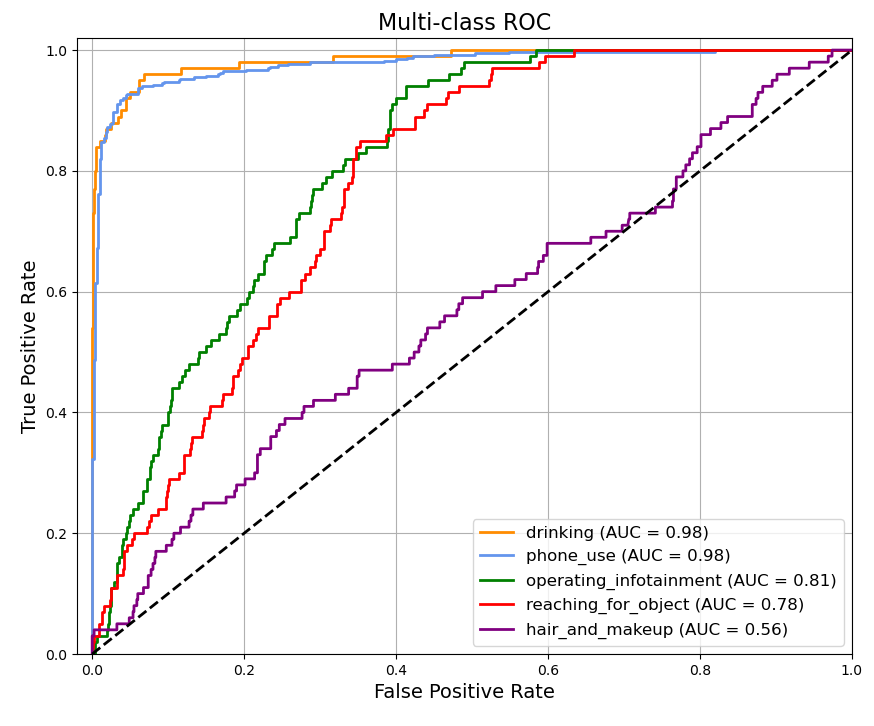
Figure 5: Multi-class ROC for additional actions
CLIP proved effective at detecting actions such as mobile phone use and eating or drinking but struggled to reliably identify actions like operating infotainment systems or reaching for objects. To further investigate this, the team generated confusion matrices (Figure 6) for the multi-class CLIP detection, first using all original categories and then excluding actions requiring determination of what the driver was reaching for.
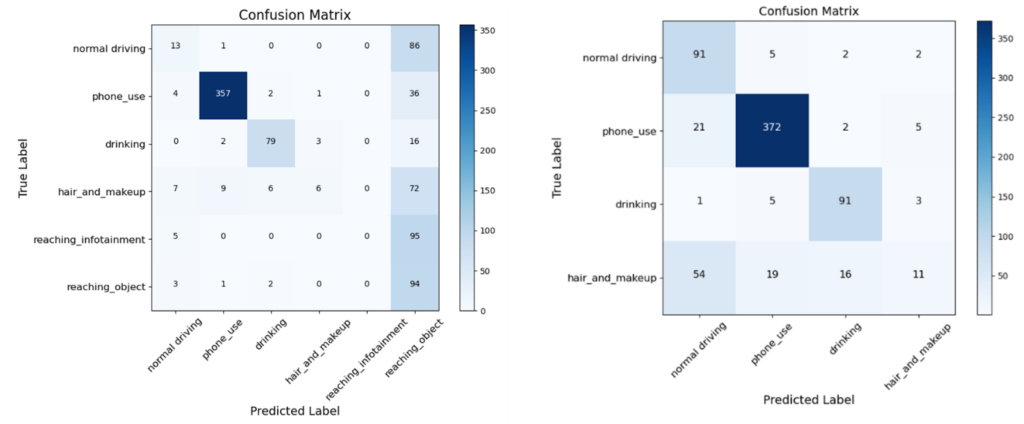
Figure 6: Confusion matrices for multi-class CLIP detection
The pre-trained CLIP model struggled to distinguish “reaching” actions from the background, likely due to inherent ambiguity—normal driving often involves reaching for an object like the steering wheel. Similarly, the “hair and makeup” category within the dataset proved unclear even to human observers, as illustrated in Figure 7, where a driver categorized as “adjusting hair or makeup” appears to be blocking sunlight instead.

Figure 7: Example “hair and makeup” distraction category which is ambiguous if the driver is actually distracted or not.
Mosaic ATM’s team validated the VLM using real-world data acquired from Touchstone, allowing them to test models under actual driving conditions. A key difference between open-source data and real-world data was the presence of passengers, which could potentially skew results. However, as shown in Figure 8, CLIP successfully distinguished between driver and passenger actions, correctly identifying the driver as engaging in “safe driving” while the passenger used a mobile device.

Figure 8: Data capture of “safe” driver and passenger using mobile device.
This process was repeated for other target categories, confirming that the VLM could differentiate driver actions from those of passengers. Due to resource constraints and a lack of annotations, the team did not conduct extensive quantifiable evaluations of this experimental data. However, qualitative assessments aligned well with earlier quantified results.
Based on these results, Mosaic ATM’s team concluded that CLIP is effective at detecting object-based actions such as mobile phone usage and eating or drinking but struggles with reaching actions. Literature suggests this is a common issue—CLIP excels at identifying specific objects within a scene (e.g., a cell phone or coffee cup) but performs poorly in more nuanced contextual tasks. Established solutions to this limitation include fine-tuning CLIP specifically for these actions or integrating a complementary pose-estimation model in early Phase II development.
OpenVINO for Gaze Monitoring
In parallel, the gaze monitoring system was developed using OpenVINO (Open Visual Inference and Neural Network Optimization), an open-source framework optimized for real-time applications for both gaze direction and PERCLOS (Percentage of Eye Closure). Developed by Intel in 2020, OpenVINO is an open-source framework for computer vision tasks, including facial recognition, eye detection, and gaze estimation. The following OpenVINO models were integrated into the workflow:
- Face-detection-adas-0001 – Detects facial bounding boxes from larger images.
- Facial-landmarks-35-adas-0002 – Generates 35 facial key points, including eyes, eyebrows, nose, mouth, and face contours. Expects a pre-cropped facial image.
- Head-pose-estimation-adas-0001 – Produces a head pose vector (x, y, z) and pitch, roll, yaw angles based on head position relative to the camera. Expects a pre-cropped facial image.
- Gaze-estimation-adas-0002 – Predicts eye gaze vectors (x, y, z). Expects two pre-cropped eye images as inputs.
- Open-closed-eye-adas-0001 – Predicts the probability of an eye being open or closed (0-open, 1-closed). Expects a single pre-cropped eye image.
This system followed a multi-step process, starting with facial detection and landmark recognition to isolate the driver’s eyes. Using these extracted features, the model estimated the driver’s gaze direction in three-dimensional space and calculated PERCLOS values to assess eye closure levels indicative of drowsiness. The gaze detection model demonstrated a mean absolute error of 7.4° in azimuth and 8.7° in elevation, while the PERCLOS classifier achieved near-perfect accuracy with an AUC of 0.9998. Running at approximately 11 frames per second, this system was confirmed to be suitable for real-time operation.
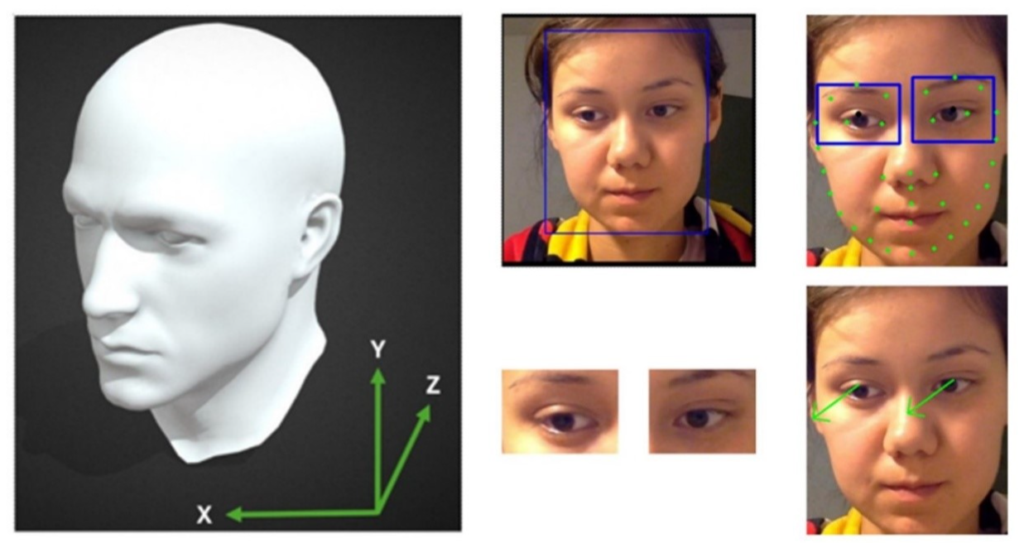
Figure 9: (left) coordinate system using for gaze detection and. (right) gaze detection CV workflow.
External Object and Lane Detection for Language Models in Automotive Safety
Next, Mosaic ATM developed two external systems—one for detecting other vehicles and vulnerable road users (VRUs) and another for detecting lane markings and distancing.
VRU and Vehicle Detection
For VRU and vehicle detection, Mosaic ATM’s team experimented with several approaches and identified MS COCO as a source of relevant object classes. The initial approach tested a pre-trained You Only Look Once (YOLO) algorithm, which was being integrated into Mosaic’s EyesOnIt product. EyesOnIt is an existing platform designed for surveillance applications, allowing users to match supplied captions to images. The platform utilized the Contrastive Language-Image Pre-Training (CLIP) model—the same model used for distracted driver action detection but within a different framework.
However, this approach lacked the ability to generate bounding boxes, a key feature for object localization. To address this limitation, the team updated EyesOnIt to optionally incorporate pre-trained YOLOv4 and region-based convolutional neural networks (RCNN) from Meta’s Detectron2 library. These models produced bounding boxes and segmented objects of interest, which were then compared against CLIP embeddings for MS COCO classes. The combined probabilities from YOLO/RCNN and CLIP comparisons enhanced detection accuracy for pedestrians, vehicles, traffic signs, and smaller objects such as handbags.
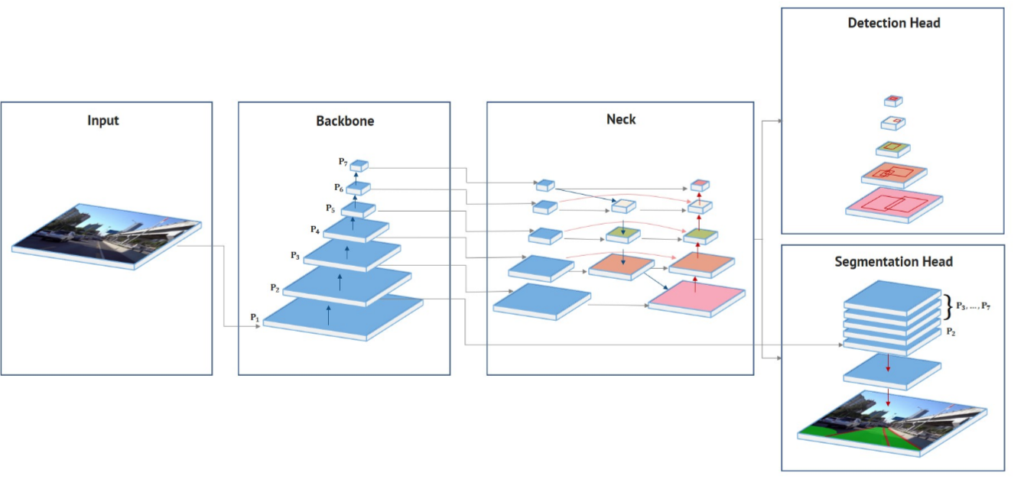
Figure 10: HybridNets architecture
Later in the project, the team identified a potential model architecture that simultaneously performed object detection and image segmentation—HybridNets. As illustrated in Figure 10, HybridNets contains an encoding backbone that feeds into both detection and segmentation heads By sharing the base network for both tasks, this is a more computationally efficient approach. A freely available, commercially friendly pre-trained model for HybridNets existed, but it was limited to detecting a single object class (cars). Since the dataset used to train this model was not available for commercial use, the team decided to leverage EyesOnIt to assist with tagging data for training a custom HybridNets model in Phase II.
Advancing Object Detection with EyesOnIt
As part of this task, the team updated the EyesOnIt video pipeline to enable bounding box overlays and generate JSON metadata files with detection results. This automated data tagging process was intended to facilitate the creation of a custom training dataset for an automotive-specific HybridNets model.
To validate this proof-of-concept, the team applied the method to real-world data supplied by Touchstone in the Detroit area, demonstrating the ability to detect various objects such as cars, trucks, pedestrians, and even animals (Figure 11).

Figure 11: External object detection of other vehicles and VRUs
Lane Detection and Distancing
For lane detection, the team initially explored the PersFormer_3DLane detection model, which was available on GitHub and had been described in a 2022 peer-reviewed article demonstrating strong performance on the OpenLane dataset. Although PersFormer was licensed under Apache-2.0, which permitted commercial use, the OpenLane dataset itself was restricted for such purposes. Consequently, the team evaluated the model using the ONCE dataset.
While PersFormer was relatively recent, newer models on the OpenLane leaderboard—such as LATR (Lane Detection with Transformer)—appeared promising, offering open-source code and pre-trained models for potential integration. However, further investigation revealed significant challenges with both models:
- LATR relied heavily on the PersFormer repository and was poorly maintained, with outdated dependencies that required substantial effort to resolve.
- Both models had highly complex network architectures that were difficult to work with and inefficient for deployment.
Despite theaccuracy, these limitations ultimately rendered them unsuitable, leading the team to explore alternative solutions.
Fortunately, the HybridNets model—previously identified for external object detection—also demonstrated applicability for lane and roadway marking detection. The model’s semantic segmentation output can separate an image into three distinct channels:
- Drivable area (roadways)
- Non-drivable area (grass, sidewalks, etc.)
- Lane markers

These three channels enabled the team to generate a color image representation (Figure 16) to visually verify the segmentation results. In Phase II, HybridNets would likely be fine-tuned further to enhance its lane detection performance. By leveraging a single model for both object and lane detection, the team anticipated improving system reliability while minimizing hardware requirements for deployment.

Figure 13: Bezier curve fitting to lanes before and after constraining the control points
To improve lane representation, the team experimented with clustering lane markers and fitting Bézier curves to the clusters (Figure 13). Initially, results were mixed due to the number of control points and the underlying algorithm’s ability to fit curves to roadway markings, particularly around intersections.
However, significant improvements were achieved later in the project by constraining the number of control points (shown in green) to a lower value. In Phase II, additional enhancements could be pursued, such as further refining the curve-fitting algorithm and porting it to C++ to optimize runtime performance.
Evaluation Metrics for Language Models in Automotive Safety
Mosaic ATM assessed multiple open-source AI models using annotated datasets and later evaluated their performance with Touchstone experimental data. These Phase I metrics served as benchmarks for refining algorithms ahead of Phase II system integration. Mosaic also provided a foundation for future upgrades and compliance checks against NTHSA and industry standards.
Gaze Detection Results
For gaze detection, Mosaic ATM computed evaluation metrics on gaze direction and open/closed eye states. Using 1,000 samples, mean absolute errors (MAE) for azimuth (7.4°) and elevation (8.7°) were recorded, aligning with literature noting elevation as more challenging to predict. The model, evaluated on the KaggleEyes dataset, demonstrated near-perfect classification of open vs. closed eyes, achieving an AUC of 0.9998, with only 19 of 3,000 samples misclassified. A separate assessment on the UnityEyes dataset showed the model correctly identified 99.965% of open eyes, but struggled with differentiating “drowsy” from “closed.” The full gaze detection routine achieved a computational time of 31ms per image, confirming feasibility for Phase II deployment.
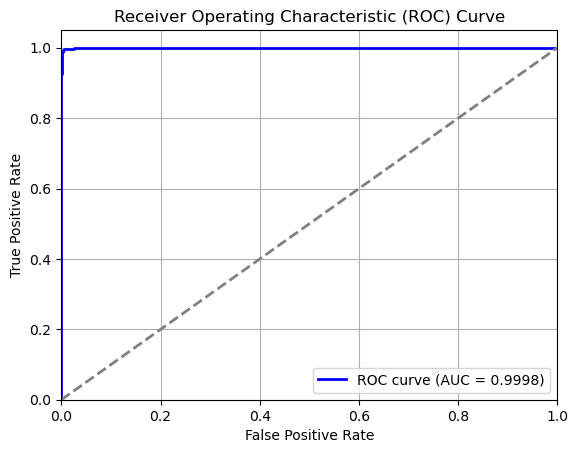
Figure 14: ROC curve for open vs closed eye states
In evaluating vision-language models (VLMs), Mosaic ATM used CLIP to analyze driver actions. While CLIP effectively identified object-based actions (e.g., mobile phone use, eating), it struggled with contextual actions like reaching for objects. Metrics showed high AUC values for phone use (0.98) and eating (0.98), but lower performance for reaching (0.76) and adjusting hair/makeup (0.56). Further fine-tuning in Phase II will focus on improving classification of reaching actions.
| Driver Action | AUC |
| Mobile phone usage | 0.98 |
| Eating or drinking | 0.98 |
| Infotainment usage | 0.81 |
| Reaching for object | 0.76 |
| Adjusting hair or makeup | 0.56 |
Table 1. CLIP categorical detection metrics via AUC.
| True Action | Normal | Cell Phone | Eating/Drinking | Hair/Makeup |
| Normal | 0.2510 | 0.2478 | 0.2501 | 0.2500 |
| Cell Phone | 0.2509 | 0.2519 | 0.2482 | 0.2489 |
| Eating/Drinking | 0.2433 | 0.2452 | 0.2655 | 0.2458 |
| Blocking Sun? | 0.2514 | 0.2462 | 0.2470 | 0.2555 |
Table 2: CLIP similarity scores from Touchstone data
Lane Detection Results
For lane detection, the LATR model was evaluated using the Once dataset, achieving an F1 score of 0.81. However, due to its complexity, Mosaic ATM pivoted to HybridNets for both lane segmentation and object detection.
| Prob Thresh | F1 | Precision | Recall | D error |
| 0.100 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.150 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.200 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.250 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.300 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.350 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.400 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.450 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.500 | 0.812 | 0.851 | 0.777 | 0.054 |
| 0.550 | 0.810 | 0.864 | 0.762 | 0.053 |
| 0.600 | 0.802 | 0.873 | 0.742 | 0.053 |
| 0.650 | 0.790 | 0.882 | 0.716 | 0.052 |
| 0.700 | 0.775 | 0.891 | 0.686 | 0.051 |
| 0.750 | 0.765 | 0.906 | 0.662 | 0.051 |
| 0.800 | 0.740 | 0.912 | 0.623 | 0.050 |
| 0.850 | 0.717 | 0.925 | 0.585 | 0.049 |
| 0.900 | 0.680 | 0.936 | 0.533 | 0.049 |
| 0.950 | 0.593 | 0.946 | 0.432 | 0.048 |
Table 3: Metrics from LATR model on the Once 3D lane dataset
Although direct performance metrics were unavailable, HybridNets demonstrated strong object detection (mAP@50% of 77.3) and intersection-over-union (IoU) scores of 90.5 for drivable areas and 31.6 for lane segmentation. Additional clustering and Bezier curve fitting showed promise for improved annotation, with further optimization planned for curved roads and intersections in Phase II.
External Object Detection Results
For external object detection, Mosaic ATM benchmarked models using the MS COCO dataset. YOLOv4 and CLIP achieved high accuracy on large objects but struggled with smaller ones. Introducing Detectron2’s Mask-RCNN improved performance across most metrics, particularly for small object detection. While this tri-model approach reduced throughput, Mosaic ATM plans to transition to HybridNets for real-time inference in Phase II, leveraging EyesOnIt’s infrastructure for deployment.
| AR | AP | IoU | Area |
| 0.236 | 0.259 | 0.50:0.95 | all |
| 0.363 | 0.398 | 0.50 | all |
| 0.386 | 0.282 | 0.75 | all |
| 0.121 | 0.084 | 0.50:0.95 | small |
| 0.446 | 0.304 | 0.50:0.95 | medium |
| 0.65 | 0.469 | 0.50:0.95 | large |
Table 4: AR and AP on MS COCO using YOLOv4 and CLIP
| AR | AP | IoU | Area |
| 0.283 | 0.35 | 0.50:0.95 | all |
| 0.41 | 0.52 | 0.50 | all |
| 0.419 | 0.383 | 0.75 | all |
| 0.232 | 0.196 | 0.50:0.95 | small |
| 0.464 | 0.397 | 0.50:0.95 | medium |
| 0.557 | 0.472 | 0.50:0.95 | large |
Table 5: AR and AP after including a Mask-RCNN
These evaluations provided critical insights for refining AI-driven perception models, laying the groundwork for operational deployment in Phase II.
Integration Considerations for Language Models in Automotive Safety
Several key insights emerged regarding system integration. The VBOX PRO hardware, used for real-world data collection, was found to be representative of the hardware needed for deployment, offering synchronized high-definition video streams at 20 frames per second. The gaze detection routine using OpenVINO proved to be robust and capable of real-time operation without significant modifications. However, VLM-based descriptions required optimization to extract quantifiable insights suitable for integration. CLIP action detection performed well for object-based tasks but required fine-tuning to differentiate nuanced driver actions. HybridNets showed strong potential for both object and lane detection, though dataset adaptations were necessary to align with real-world automotive environments.
Conclusion: Looking Ahead at Language Models in Automotive Safety for Phase II
Phase I of the VILMAS project successfully demonstrated the feasibility of integrating VLMs, gaze tracking, and deep learning to create a holistic driver readiness assessment system. By validating models for gaze monitoring, driver action classification, and external object detection, the project established a strong foundation for future development. These advancements address critical gaps in current automotive safety technologies, offering a more comprehensive and proactive approach to reducing driver distraction and improving road safety.
Looking ahead to Phase II, the focus will be on refining and integrating these standalone models into a seamless, real-time system capable of providing actionable safety interventions. Further fine-tuning of CLIP and HybridNets will enhance accuracy, while human factors research will guide the development of a dynamic driver readiness score. Additionally, Mosaic ATM aims to strengthen industry partnerships and explore commercialization strategies to ensure VILMAS can be effectively integrated into existing automotive safety ecosystems. With these advancements, VILMAS is poised to set a new standard for AI-driven driver monitoring, enhancing vehicle safety and reducing risks on the road.